認識 Google Cloud Dataproc
Dataproc 是什麼?
Dataproc 是 GCP 的一個全代管的大數據處理服務,它支援開源的大數據生態系統工具,如 Apache Spark、Hadoop、Hive 等。
簡單說,Dataproc 幫你把資料處理這件事,變得又快又簡單,就像把一座沉重的工廠裝進自動販賣機,按一下就能開工。
為什麼選擇 Dataproc?四大優勢
1. 快速啟動與彈性擴展:只需幾分鐘就能啟動叢集,根據工作負載自動擴縮。
2. 與 GCP 生態系整合:無縫串接 BigQuery、Cloud Storage、Vertex AI 等工具。
3. 精準付費、節省成本:按秒計費、支援自動關閉機制,有效降低閒置成本。
4. 使用你本來就會的技能: Dataproc 包含 Hadoop、Spark、Hive、Pig 等 Open Source 的工具,不用重新學習。
Dataproc 的應用場景
大數據處理
無論是 ETL(Extract, Transform, Load)處理,還是資料清洗、彙整,都可以用 Dataproc。
結合 Spark 進行機器學習訓練
Dataproc 支援 Spark MLlib,你可以直接在叢集上進行分散式訓練,大幅提升訓練速度與模型精度。
搭配 Jupyter Notebook 做互動分析
開發者可透過 Jypyter Notebook 與叢集互動,實現即時查詢與分析,彷彿在大型資料倉庫裡漫步,探索資料的可能性。

Dataproc 的架構設計概念
叢集(Cluster)與節點角色說明
Dataproc 叢集主要包含兩種節點角色:Master 與 Worker。就像一個工廠,Master 是主管,Worker 是執行員工。
而節點其實就是 Compute Engine 的虛擬機器,因為我們是對整個 Cluster 操作,不針對某一台 VM,所以我們才稱它們叫 Node。
Master 節點與 Worker 節點的差異
- Master:負責指派任務、監控進度、管理資源。
- Worker:實際執行 Spark Job 與 Hadoop Task。
如何選擇正確的 VM 類型?
n2-standard 適合大多數應用。
e2-medium 適合成本敏感的小型專案。
可依工作負載選擇是否搭配 GPU 或高記憶體,但如果是初學者,建議不要開太大的機器喔!
Spark、Hadoop、Hive 在架構中的定位
- Spark:主力計算框架,支援即時與批次任務。
- Hadoop HDFS:用於資料儲存與分散處理。
- Hive:提供 SQL 介面查詢 HDFS 中的資料。
實際操作:如何建立一個 Dataproc Cluster (叢集)
在 GCP Console 上建立步驟
進入 Dataproc => Cluster。
選擇 Compute Engine。

給 Cluster 命名,選擇 Region 和 Zone,我是照 《Dataproc: Qwik Start – Console》 這個 Lab 做的,所以就跟它一模一樣,你也可以選擇台灣 asia-east1 喔!

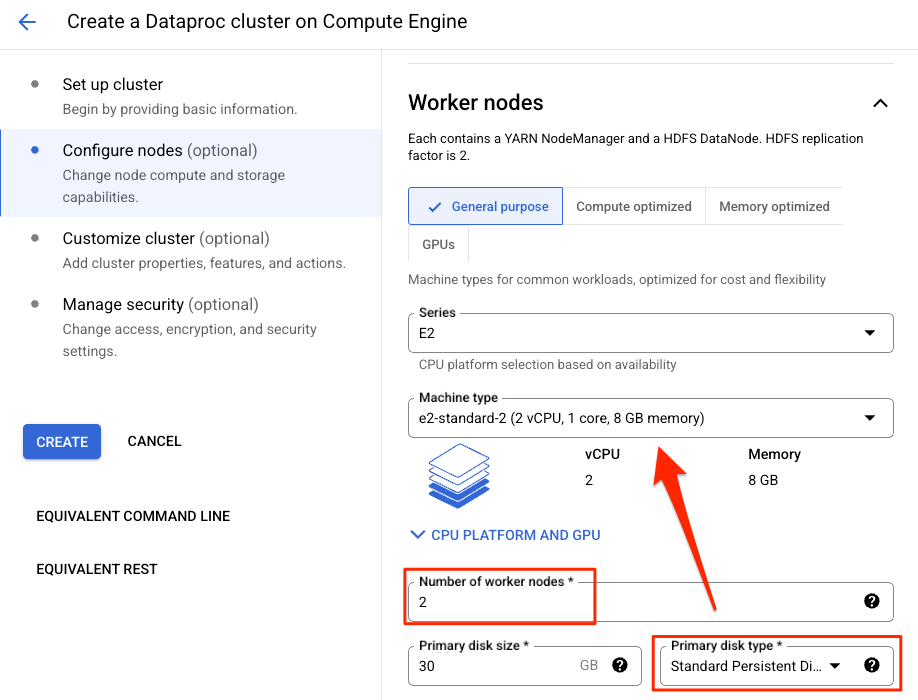
先設定 Manager Node,我還是習慣叫 Master Node。
這裡要注意,剛開始你可能會找不到 N1、N2 或 E2 的主機,你要先把 Disk 改成 Standard 的,這幾個型號就會出現了。

一樣的做法再設定 Worker Node。
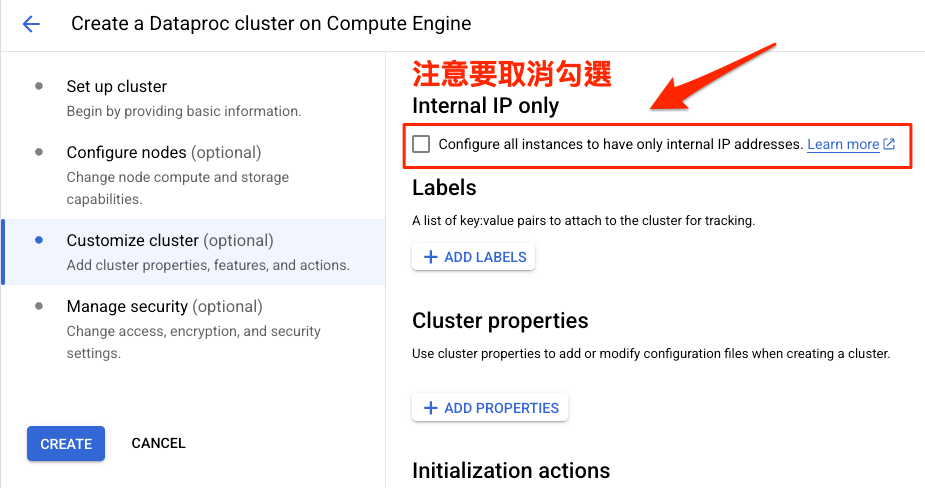
在 IP 的部分,原本 「Internal IP only」是有勾選的,要把它取消喔,
如果只有內部 IP,是不容易從部外連進去的,
它會先勾選,我想是為了安全性的問題,怕任何人都可以連到 Dataproc,
但我們是初學者,玩一下就會馬上把它刪掉(記得喔),所以沒關係!
接下來等大概五分鐘左右,它就準備好了。

同時你也可以在 Compute Engine 頁面上看到真的有機器開出來,一台 Master Node,兩台 Worker Node。

接下來有兩種操作場景。
第一種是直接連到 Dataproc Master Node 的 Command Line
(本部份取自網路上的 YouTube 影片:GCP Dataproc Cluster creation | HDFS and Hive)
先 SSH 連到 Master Node,然後上傳一個要分析的檔案。

進入 Hive 建立資料庫名叫 “vehicle”。

建立表格 “vehicle_sold”,並查詢表格結構。

接下來使用語法來查詢資料,看到能正常顯示剛上傳的資料。
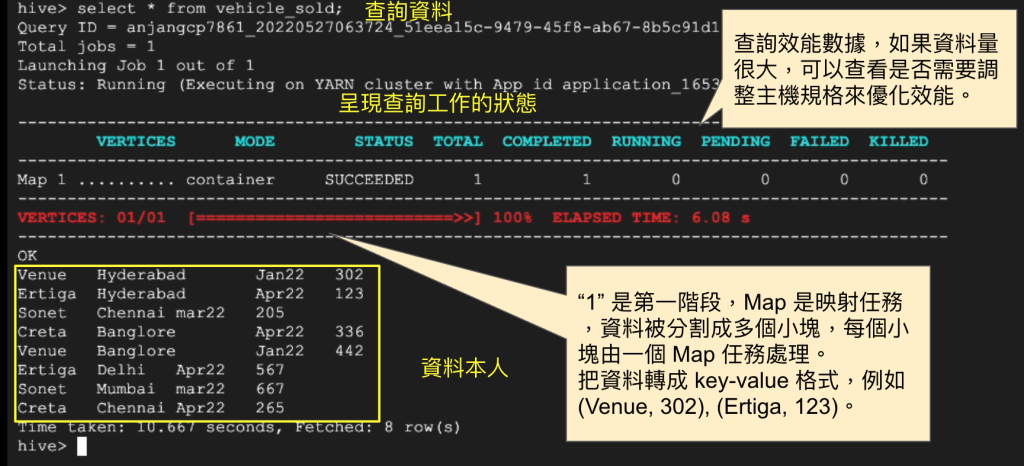
你會在上半部看到效能數據,如果資料量很大,可以查看是否需要調整主機規格來優化效能。
其中 Map 1 是什麼意思?
“1” 是第一階段,Map 是映射任務,資料被分割成多個小塊,每個小塊由一個 Map 任務處理。
把資料轉成 key-value 格式,例如 (Venue, 302), (Ertiga, 123)。
最後來下一個加總語法,查詢各類汽車銷售數量。
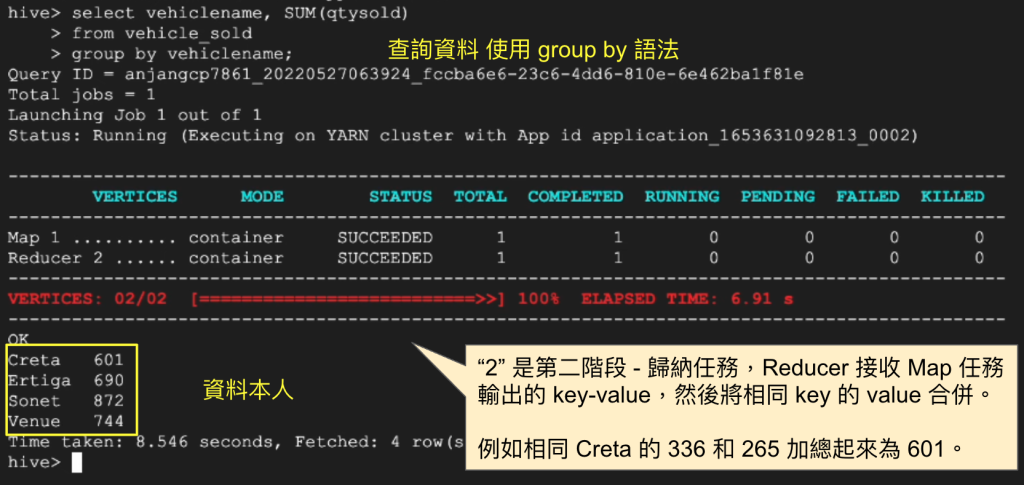
“Reducer2” 是第二階段 – 歸納任務,Reducer 接收 Map 任務輸出的 key-value,然後將相同 key 的 value 合併。
例如相同 Creta 的 336 和 265 加總起來為 601。
以上是第一種使用場景,就是讓你可以用下指令的方式,跟 Dataproc 互動操作。
第二種場景是提交你寫好的 Job 程式碼給 Dataproc 自動執行
(本部分是我操作 Skillboost Lab:Dataproc: Qwik Start – Console 的截圖)
接下來去 Jobs,我們要準備提交一個 Job。
在這個 Lab 我們要用一支程式去計算圓周率,所以要引入一個 org.apache.spark.examples.SparkPi 這個 Class,
然後再給它執行 Job 細節的程式碼檔案:file:///usr/lib/spark/examples/jars/spark-examples.jar
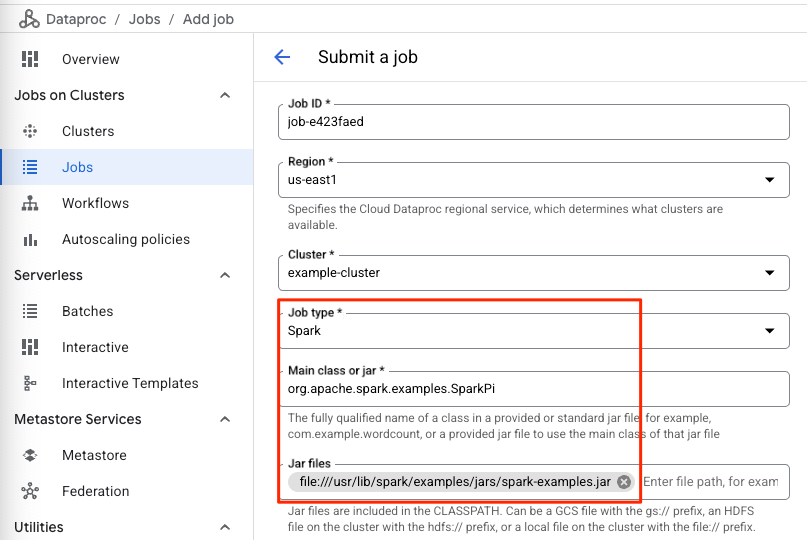
這個程式使用蒙地卡羅方法(Monte Carlo Method)來估算圓周率(Pi)的值,
參數 1000 代表程式將生成的 x,y 座標點對的數量,生成的點對越多,估算的圓周率值就越精確。
所以,當你在 Arguments 欄位中輸入 1000 時,您實際上是在告訴 SparkPi 程式生成 1000 個隨機點來估算 Pi 值。
如果您輸入更大的數字(例如 10000 或 100000),估算會更精確,但計算時間也會更長。

最後我們會在 Job Details 看到它算出來的圓周率,你會看到它有點不準。
我們記得 Pi 是 3.1415926……,但它算出來竟然是 3.14193…….
因為它只算 1000 個點,所以沒那麼準,如果算更多個點,一定比我們記憶的還準。
Dataproc 和 Dataflow 很像?到底有何差異?
當你在 Dataproc 上執行 Spark Job 時,確實會有一些操作方式上的相似點:
- 兩者都能執行預先編譯好的程式(JAR 檔案、Python 腳本等)
- 兩者都能處理批次和串流資料
- 兩者都能自動分散工作負載到多個節點
但根本差異仍然存在。
Dataproc 執行 Spark 程式時:
- 你要先建立和維護 Dataproc Cluster
- 使用
gcloud dataproc jobs submit spark或通過 Web UI 提交 JAR 檔 - Spark 程式會在你開好的 Cluster 上執行
- 叢集資源是固定的(除非手動調整)
- 叢集在任務完成後繼續存在(除非配置為自動刪除)
Dataflow 執行 Apache Beam 程式時:
- 不用預先建立 Cluster
- 提交程式後,Dataflow 會自動建立和管理執行環境
- 資源會根據工作負載 Autoscale
- 任務完成後,所有資源會自動釋放 (刪除 Cluster)
簡言之,Dataproc 執行 Spark 程式時,你仍需管理基礎架構 (Cluster),而 Dataflow 則完全幫你管理這一層面。
這就是為什麼在某些使用案例中,兩者看起來很相似,
都是提交預先寫好的程式來處理資料,但底層的資源管理和架構哲學是不同的。
Dataproc 和 Dataflow 比較表

工作流程範本 Dataproc Workflow Template
自動化任務排程的關鍵利器
Workflow Templates 用來設定和管理一系列相依的 Dataproc 作業 (Job),
例如 A Job 必須完成之後,再開始 B Job。
就像食譜,你只需設定好步驟與材料,系統會自動幫你依序完成資料處理任務。
注意建立範本後,Dataproc 不會建立 Cluster 或開始運作。只有在建立機器後才會開始工作。
工作流程範本的種類
代管叢集 Managed Cluster
當你手上沒有運作中的 Cluster,工作流程會建立一個「臨時」Cluster 來運行作業,完成時刪除該 Cluster。
叢集選擇器 Cluster Selector
當你手上有幾個運作中的 Cluster,你可以下標籤來指定做事的 Cluster,有點像 Kubernetes 那種管理方法。
每個 Cluster 都可以設標籤,是 key-value 的結構,例如你有 3 個 Cluster:
cluster-1 的標籤 analytics=ig
cluster-2 的標籤 analytics=fb
cluster-3 的標籤 web=click
你指定 analytics=fb,cluster-2 就會開始做事。
它會選具有完全相同標籤的 cluster 來工作,而且會找具有最多 YARN 可用記憶體的叢集來運行所有工作流程作業。
但工作完,Cluster 會持續存在,不會把你的 Cluster 刪掉。
Dataproc 與其他 GCP 工具整合
結合 BigQuery 快速查詢分析結果
Dataproc 可以使用 BigQuery 連接器在 Spark 或 Hadoop 作業中直接讀寫 BigQuery 資料。
處理完的結果可直接匯入 BigQuery,進行後續報表分析與視覺化。
如果經常使用 Dataproc、Cloud Storage 和 BigQuery,建議使用 Avro 格式的資料,因為完全相容。
與 Cloud Storage 無縫資料串接
傳統上 Hadoop 用 HDFS 在資料的永久儲存,確保資料在系統關閉或重啟後仍然存在。
在 Dataproc 上使用 Cloud Storage 連接器時,可以讓 Dataproc 直接讀寫儲存在 Cloud Storage 上的資料,
無需使用 HDFS。(因為 Dataproc 通常用完就會刪掉環境,上面的 Disk 跟著刪除)
而且 GCS 還比 Disk 便宜。
你可以再搭配 GCS 的物件生命週期管理 Object Lifecycle,有效控管儲存成本。
成本管理與效能最佳化技巧
如何利用預留節點與自動關機功能省錢
使用 Preemptible VM(可搶占節點)節省 80% 成本,但這種主機可能隨時被終止。
建議你用在容錯性高的批次處理工作(可以隨時停下來、即使失敗也可以重試、有備份機制),
也就是「不緊急不重要的工作」。
建議搭配重試機制和優雅停用 (Graceful Decommissioning) 設定,確保正在進行的工作在節點移除前完成。
使用 Cloud Logging 監控資源與效能
透過指標追蹤 CPU、Memory 使用率,找出瓶頸,優化叢集配置。
Dataproc 常見錯誤與排除方式
排查任務失敗的三個關鍵檢查點
- 驗證 Cluster 資源是否足夠,像記憶體是不是快爆了。
- 檢查程式碼是否有錯誤。
- 檢查輸入資料路徑是否正確。
如何讀懂 Job Logs 與錯誤訊息
進入 Job Logs,根據錯誤訊息回推失敗原因,例如記憶體不足、格式錯誤、路徑遺失等。
你也可以直接錯誤的 Log 拿去問 ChatGPT。
適合導入 Dataproc 的企業情境
金融業:批次風險模型計算
金融機構常需夜間批次執行大量風控模型,Dataproc 正好適合這種短時高負載任務。
零售業:銷售資料彙總與推薦引擎訓練
從 POS 資料中彙總趨勢、訓練推薦模型,Dataproc 可有效協助行銷與庫存預測。
當然,可以做批次處理的工具都可以,像上面提到的 Dataflow,取決於你對哪個比較熟悉。
結語:Dataproc 是否適合你的團隊?
如果你的團隊正在處理大量資料,需要彈性資源、自動化流程,
或正從傳統平台轉型到雲端,那麼 Dataproc 將會是你強而有力的幫手。
它不只是工具,更是未來資料基礎建設的基石。
常見問答(FAQ)
Q1:Dataproc 可以不寫程式嗎?
A:可以透過 Workflow Template 搭配 SQL、Hive 指令,降低程式依賴。(所以還是要拿下指令)
真的要不寫程式,可以考慮用 Dataprep,它是互動式並且視覺化的操作界面,可以設定資料處理規則讓它自動執行。
Q2:Dataproc 和 BigQuery 哪個適合分析?
A:BigQuery 適合即時分析,Dataproc 則擅長處理大量轉換、清洗、模型訓練等流程,Dataproc 的分析,主要是拿來探索用的,就是讓你大概看一下資料長怎樣,不方便做大規模而且複雜的分析。
Q3:有支援 GPU 計算嗎?
A:有,可以在 Worker 節點指定使用 GPU 運算資源。
Q4:Dataproc 支援 Python 嗎?
A:完全支援,Spark 任務可用 PySpark 寫成,也可整合 Notebook 開發環境。
Q5:部署後多久能用?
A:幾分鐘內即可建立好叢集,立即上線處理任務。