Spotify 雲端遷移 GCP 的 7 大技術決策一覽:
| 決策主題 | 選擇 | 核心原因 |
|---|---|---|
| 遷移策略 | Lift and Shift + Rewrite 並行 | 停機代價決定做法 |
| 容器管理 | 自研 Helios → GKE | 消除 Toil,CPU 使用率翻倍 |
| 強一致性資料 | Cloud Spanner | 全球同步、銀行等級一致性 |
| 大量寫入資料 | Cloud Bigtable | 播放紀錄的 Append-heavy 場景 |
| 音訊檔案 | Cloud Storage + CDN | 全球低延遲傳輸 |
| 資料分析 | Hadoop → BigQuery | 查詢從小時縮為分鐘 |
| 事件傳遞 | Pub/Sub + Dataflow | 推薦演算法的即時資料餵養 |
一、為什麼 Spotify 要把機房搬到 GCP?
1.1 自建機房的核心痛點:容量規劃跟不上成長速度
Spotify 用戶從幾百萬成長到幾億,自建機房出現兩個致命問題:
問題一:容量規劃太慢。 流量爆增時,得先訂機器、等到貨、安裝、設定,流程少則幾週、多則幾個月。 網路流量不等人。
問題二:工程師時間全被吃掉。 機器壞了要換、系統有漏洞要自己修、軟體版本要自己升級。 做一百次,產品也沒有變更好,只是維持現狀。
2016 年,Spotify 決定把基礎設施維護工作交給 Google,讓自己的工程師去開發新功能。
1.2 遷移的核心挑戰:系統不能停
每一秒都有幾千萬用戶在聽歌。 停機哪怕五分鐘,就是幾千萬人同時看到錯誤畫面。
這個前提,決定了後面所有技術決策的方向。
二、GCP 雲端遷移策略:Lift and Shift vs. Rewrite
2.1 Lift and Shift(直接搬):核心播放功能
原封不動搬過去,不改任何程式碼、不動任何架構。
適用場景: 一停就出事的核心服務。 任何改動都是風險,先求搬過去,不求完美。
2.2 Rewrite(趁機重寫):資料分析系統
搬家的同時,把 Hadoop 整個換掉,改用 BigQuery 和 Dataflow。
適用場景: 出問題代價相對可控的內部系統。 反正都要搬了,順手把舊包袱一起處理掉。
2.3 判斷標準只有一個
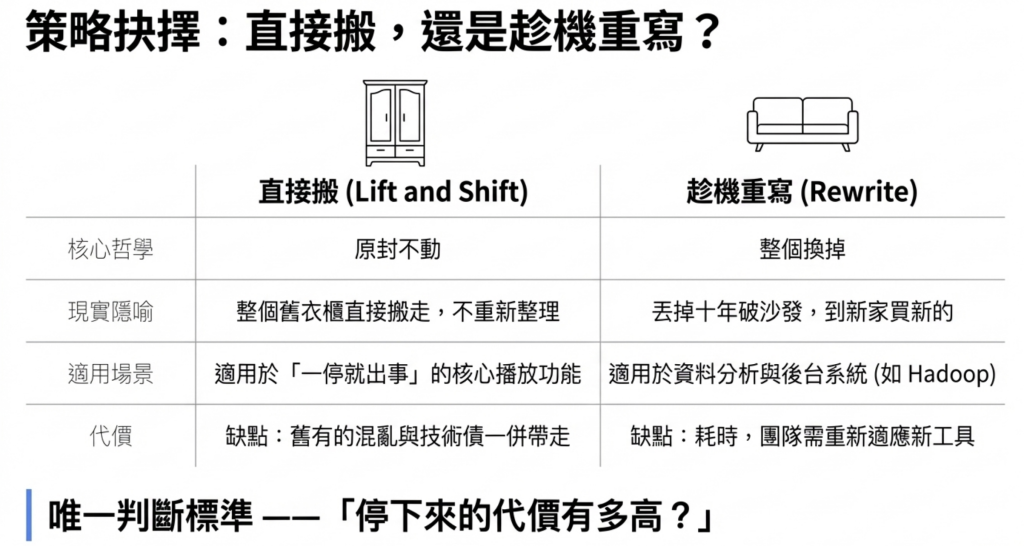
這個服務如果在遷移中出問題,代價是什麼?
代價極高 → Lift and Shift,把風險降到最低。 代價可以接受 → Rewrite,一步到位。
完整搬遷可參考此文章:《地端主機如何搬上GCP?各種方法和步驟詳解》
三、GKE 容器管理:從自研 Helios 到 Google 全代管
3.1 什麼是 Control Plane?
Spotify 的產品不是一個大程式,而是幾百個小程式組成的。
誰決定哪個程式跑在哪台機器上? 誰決定流量爆增時要多開幾個副本? 誰決定這台機器掛了,要把程式搬去哪?
這個負責做決策的角色,就是 Control Plane。
3.2 Helios 的問題:Toil
Spotify 原本有自研的 Control Plane,叫做 Helios。 功能沒問題,但維護非常累。
每次 Linux 有安全漏洞,Spotify 要自己分析、自己開發修補、自己測試、自己部署。 每次版本升級,要自己測所有相容性。 出了問題,要自己找原因、自己修。
這種「重複做、做了系統也沒有變更好」的維運工作,叫做 Toil。 Toil 是工程師效率最大的殺手。
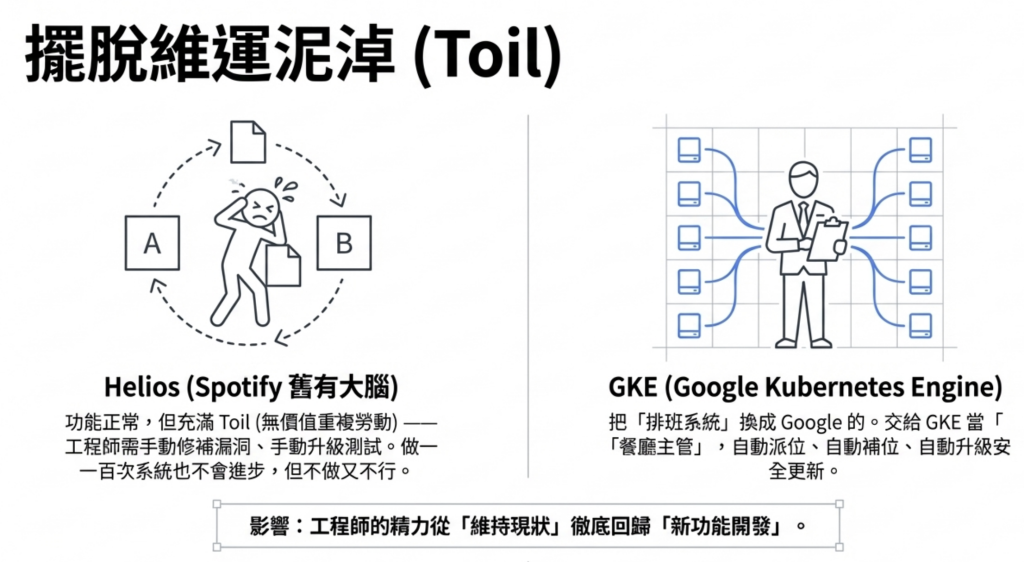
3.3 換用 GKE:CPU 使用率從 10% 提升到 20-25%
Google 接管 Control Plane 後,安全更新、版本升級全部自動處理。
但 GKE 帶來的不只是省力,還有意外的效能提升:CPU 使用率從約 10% 提升到 20-25%。
這來自 Bin Packing(裝箱最佳化)。
以前每個服務獨佔一台機器,大部分時間閒置。 GKE 把多個服務智慧塞進同一台機器,讓每台機器都跑得飽。 同樣的工作量,需要的機器更少,費用自然降了。
3.4 GKE 計費方式:選錯差很多
資源型計費: 按程式實際佔用多少資源收費。適合一般 Web 服務。
節點型計費: 按你開了幾台機器收費。適合需要指定特定硬體(例如 GPU)的情況。
Spotify 需要用 GPU 跑 AI 推理,選的是節點型計費。 使用情境不同,兩種計費方式的費用差距可能非常顯著。導入前一定要先評估清楚。
四、三層資料儲存架構:不同資料用不同工具
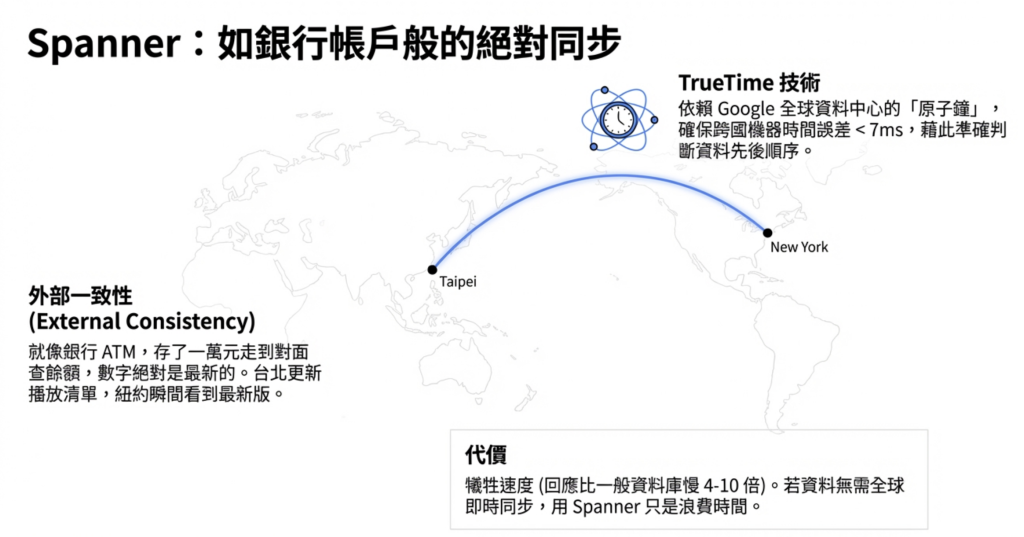
4.1 Cloud Spanner:播放清單與帳號的全球一致性
負責的資料: 播放清單、帳號資料。
核心需求:全球一致性。
你在台北更新播放清單,加了一首歌。 你在紐約的朋友馬上開 Spotify,看到的應該是最新版本。
這個特性叫做 External Consistency(外部一致性)。 Spanner 是少數能提供這個保證的資料庫。
背後技術:TrueTime
Spanner 在全球所有資料中心安裝原子鐘,確保所有機器的時間誤差不超過 7 毫秒。 靠這個保證,才能準確判斷全球資料的先後順序。
代價: Spanner 的回應速度比一般資料庫慢 4 到 10 倍。 資料不需要全球即時同步的話,用 Spanner 只是白花錢。
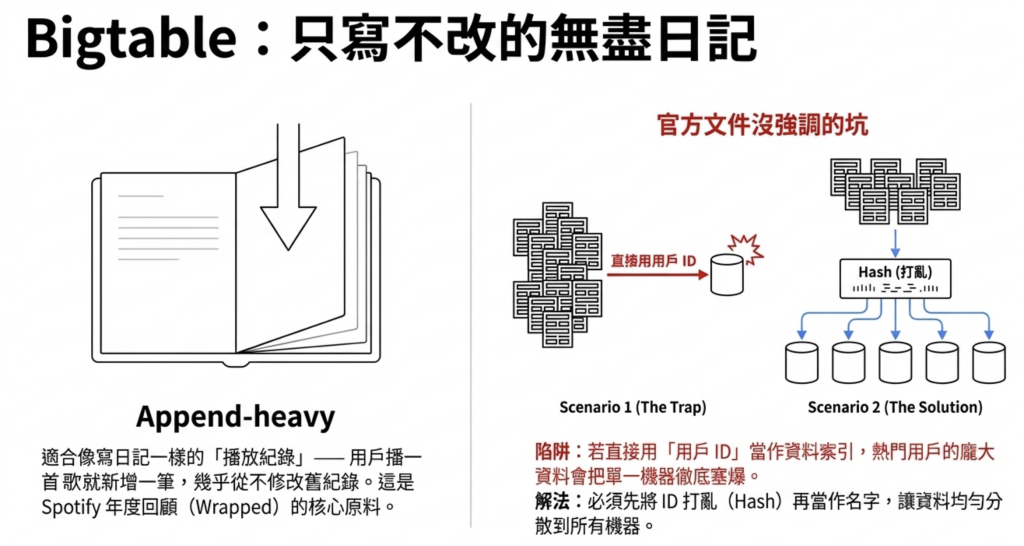
4.2 Cloud Bigtable:播放紀錄與 Wrapped 年度回顧
負責的資料: 播放紀錄、歌曲播放次數。
核心需求: Append-heavy(大量新增)的場景。
用戶每播一首歌,就新增一筆紀錄。 幾乎不需要修改或刪除舊紀錄。
這些播放紀錄累積起來,就是每年 Spotify Wrapped 的原料。
設計細節:Key 要先 Hash
直接用用戶 ID 當 Key 會出問題。 熱門用戶的資料會集中在少數幾台機器,那幾台機器撐不住,效能就下降。
Spotify 的解法:先把用戶 ID 打亂(Hash)再當 Key,讓資料均勻分散。
這個細節官方文件裡有寫,很多人跳過,等到系統出問題才回頭翻,改架構的代價很高。
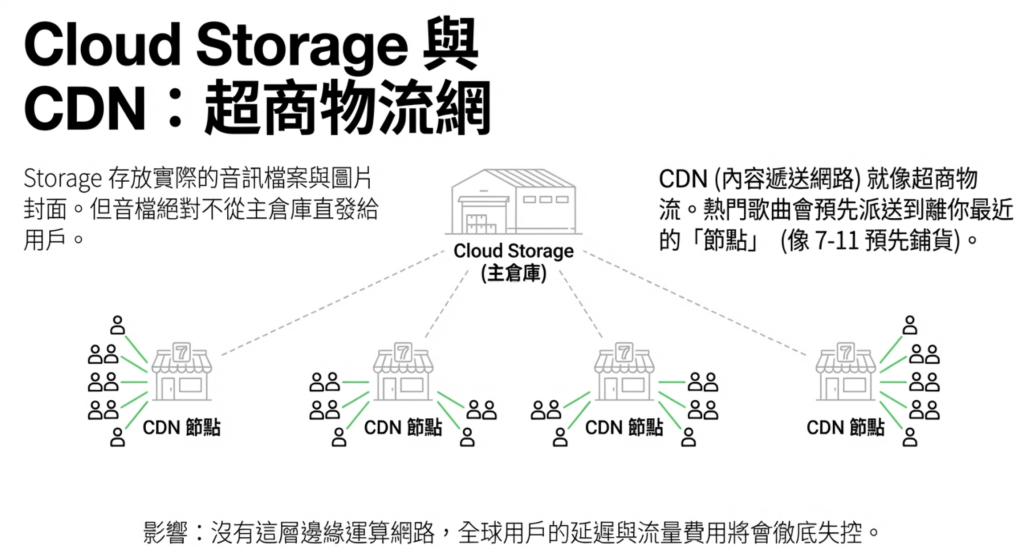
4.3 Cloud Storage + CDN:音訊檔案全球傳輸
負責的資料: 音訊檔案、封面圖片。
音訊檔案不是直接從 Cloud Storage 傳給用戶,中間還有一層 Cloud CDN。
CDN 把熱門歌曲的音訊檔案預先放到離用戶最近的節點。 台北的用戶聽歌,資料從台灣本地節點傳來,不用繞到美國,延遲短、速度快。
沒有 CDN 這層,全球幾億用戶的請求全打到同一個地方,跨洲頻寬費用就會讓帳單失控。
五、BigQuery:資料查詢從幾小時縮為幾分鐘
5.1 從 Hadoop 到 BigQuery
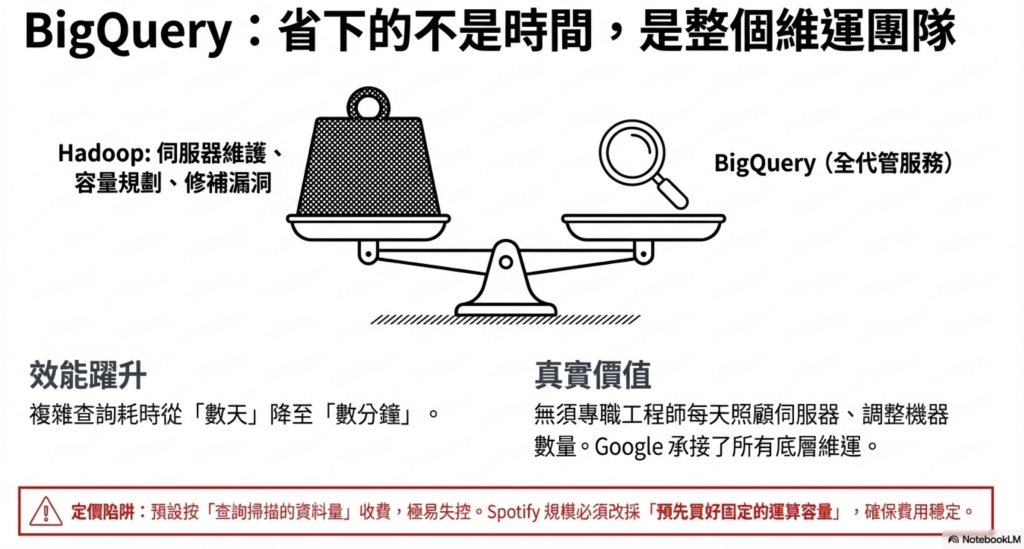
Hadoop 有兩個明顯缺點:
速度慢: 複雜查詢需要幾小時,有時幾天。
維運人力高: 需要專職工程師每天照顧,調整機器、處理卡住的任務、管理版本升級。
換成 BigQuery 之後:
查詢速度: 同複雜度的查詢,從幾小時縮短到幾分鐘。 維運人力: BigQuery 是全代管服務,基礎設施的維護、擴容、備份、升級,Google 全部處理。
5.2 BigQuery 定價:按量計費 vs. 固定容量
按量計費(預設): 每 TB 約 6.25 美元。適合資料量小的公司。
固定容量計費: 預先購買運算容量,費用可預測。適合資料量大、使用量穩定的公司。
Spotify 這種規模早就改成固定容量計費了。
如果你的 BigQuery 帳單一直在漲,研究一下固定容量選項。 有時候一個計費方式的調整,就能讓帳單砍半。
了解更多 BigQuery 可參考:《BigQuery 是什麼?功能、組成元件、特色和優勢完整介紹》
六、Pub/Sub + Dataflow:事件驅動架構的兩個設計眉角
6.1 At-least-once Delivery:同一則訊息可能送兩次
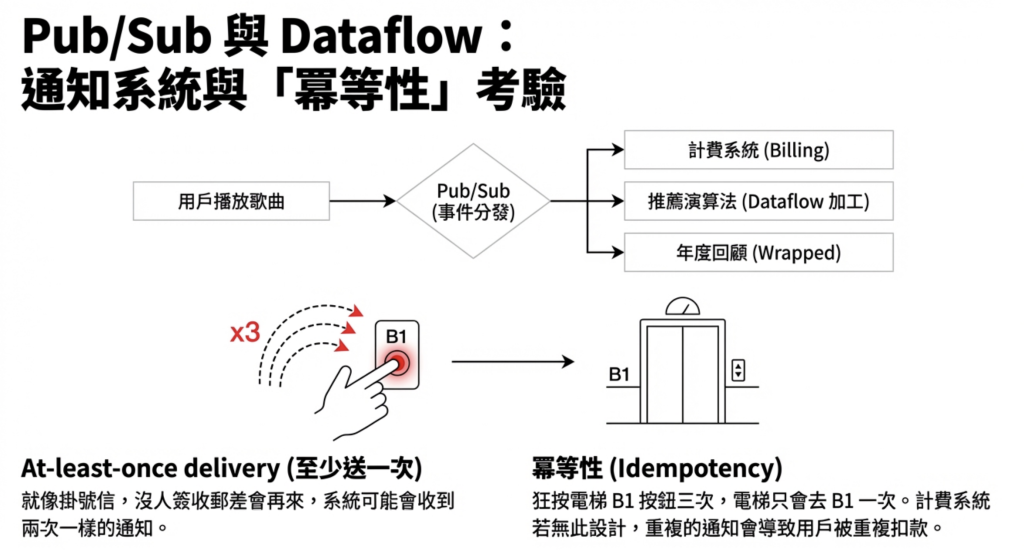
用戶播一首歌,會觸發一連串反應: 計費系統扣版稅、推薦系統更新喜好模型、播放紀錄系統記錄這次播放。
負責傳遞這些通知的是 Pub/Sub。
Pub/Sub 的特性:At-least-once Delivery(至少送達一次)。
它保證訊息一定送到,但在網路不穩定、接收方沒及時確認的情況下,同一則訊息可能送兩次甚至更多次。
了解 Pub/Sub 更多可參考《Cloud Pub/Sub 教學:比 RabbitMQ 好用,無限擴充的訊息佇列服務》
6.2 冪等性(Idempotency):計費系統的必要設計
訊息可能重複,計費系統就必須有 冪等性。
「用戶播放 A 歌曲」的通知,就算送來三次,系統只能扣一次版稅、記錄一次播放。
實作方式有兩種:
一、每個事件附加唯一 ID(Event ID),收到訊息前先確認這個 ID 有沒有處理過。 二、把操作設計成「就算重複執行,結果也不變」的形式。
任何依賴事件驅動架構的系統,冪等性不是選配,是必須的。
6.3 Dataflow:推薦演算法的資料來源
Dataflow 把即時的播放記錄和用戶歷史行為合併,做計算和轉換,把結果餵給推薦演算法。
Dataflow 處理的是 串流資料(Streaming Data),也就是即時、持續湧入的資料流。 這讓推薦系統能快速響應用戶的行為,你剛聽完一首歌,推薦結果很快就會反映。
七、VPC 網路架構:一個初期沒注意的限制,代價極高
7.1 VPC Peering 不支援 Transitive Routing
Spotify 的每個工程團隊有獨立的 GCP 專案,用 VPC Peering 讓不同團隊的服務互相通訊。
VPC Peering 有一個關鍵限制:不支援 Transitive Routing(轉傳路由)。
A 網路和 B 網路打通了、B 網路和 C 網路打通了。 但 A 網路的服務,不能透過 B 網路去存取 C 網路。 A 和 C 之間必須再建立一個獨立的 VPC Peering 連線。
服務只有幾個時,影響不大。 服務成長到幾百個、幾千個,需要互相連線的組合數量就會爆炸性增長,管理幾千條 Peering 連線本身就是巨大的維運負擔。
網路架構設計要在初期就考慮擴展性。 等問題出現再來改,代價是初期就設計好的幾十倍。
7.2 Workload Identity:容器的存取權限管理
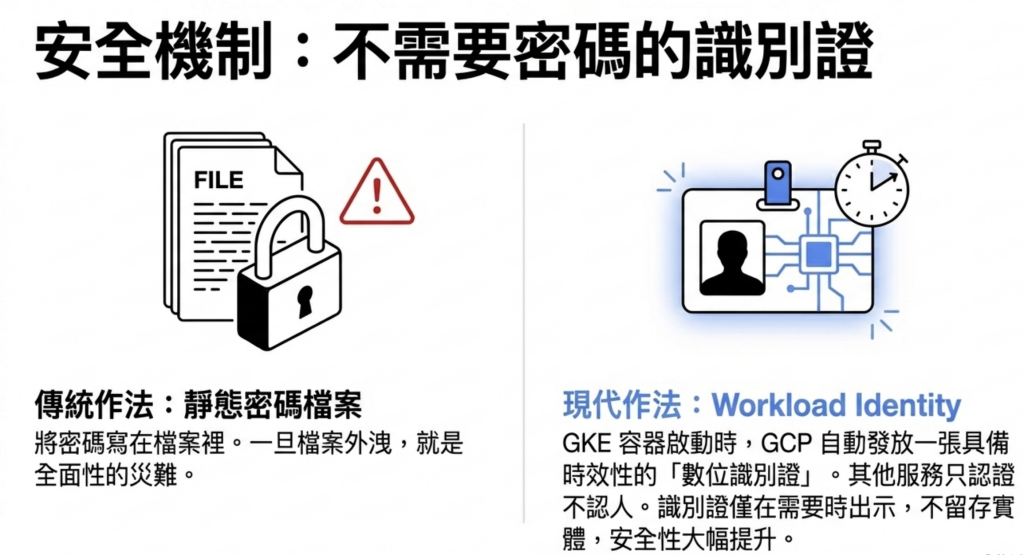
GKE 的 Workload Identity 讓容器安全存取 GCP 上的其他服務。
每個容器啟動時,GCP 自動發給它一組識別憑證,記錄這個容器有哪些存取權限。
相比傳統做法(把密碼寫在設定檔裡)的優勢: 設定檔傳錯地方、被包進映像檔推上公開倉庫,都可能造成嚴重的安全事故。 Workload Identity 的憑證不存在任何地方,大幅降低外洩風險。
速查表:這篇文章的判斷框架
| 問題 | 答案 |
|---|---|
| 遷移時,這個服務停下來的代價高不高? | 高 → Lift and Shift;低 → Rewrite |
| 資料需要全球即時一致? | 是 → Cloud Spanner;否 → 考慮其他方案 |
| 資料是大量寫入、幾乎不修改? | 是 → Cloud Bigtable |
| BigQuery 帳單一直在漲? | 評估固定容量計費 |
| 事件驅動架構的業務邏輯 | 冪等性是必須的,不是選配 |
| 網路架構設計 | VPC Peering 不支援 Transitive Routing,初期就要考慮進去 |
常見問題 FAQ
Q1:Spotify 的雲端遷移總共花了多少時間? Spotify 從 2016 年開始將服務逐步遷移到 GCP,到 2023 年時已幾乎完成整個遷移過程,前後歷時約七年。這麼長的時間,主要是因為遷移過程中服務不能中斷,必須以滾動式、漸進式的方式進行。
Q2:什麼是 Lift and Shift?適合哪種情境? Lift and Shift 是一種雲端遷移策略,指的是將服務原封不動地搬到雲端,不修改任何程式碼或架構。這種方式最適合「停機代價非常高」的核心服務——因為任何改動都是風險,直接搬過去能把遷移風險降到最低。代價是舊有的技術債也會一起帶過去。
Q3:GKE 是什麼?和自己管理 Kubernetes 有什麼差別? GKE(Google Kubernetes Engine)是 Google 提供的全代管 Kubernetes 服務。和自己管理 Kubernetes 最大的差別在於:安全更新、版本升級、Control Plane 的維護,全部由 Google 負責,使用者只需要專注在自己的應用程式上。這能大幅減少工程師花在維運上的 Toil 時間。
Q4:Cloud Spanner 的外部一致性(External Consistency)和一般資料庫有什麼不同? 一般的分散式資料庫通常提供的是「最終一致性」(Eventual Consistency)——也就是資料更新後,不同節點的資料可能有短暫的不一致,但最終會同步。Spanner 的外部一致性提供更強的保證:一筆資料寫入之後,全球任何地方的讀取都能立刻看到最新的版本,就像銀行帳戶的操作一樣。
Q5:Bigtable 的 Key 設計為什麼重要? Bigtable 會把相近的 Key 存放在同幾台機器上。如果直接用連續性的 ID 當 Key(例如遞增的用戶 ID),熱門用戶的資料就會集中在少數機器上,造成「熱點」問題,讓那幾台機器過載、整體效能下降。先對 Key 做 Hash 處理,可以讓資料均勻分散到所有機器,避免熱點。
Q6:什麼是 Toil?工程師為什麼要減少它? Toil 指的是重複性的、手動的、對系統沒有長期改善效果的維運工作。例如每天手動重啟某個服務、手動處理積壓的任務、手動更新設定檔等。Toil 不只讓工程師感到無聊和挫折,更重要的是它直接佔用了工程師的時間,讓他們沒有精力去做真正有創造力、有長遠價值的工作。
Q7:Pub/Sub 的 At-least-once Delivery 為什麼不設計成 Exactly-once(剛好一次)? Exactly-once 的保證在分散式系統中實作成本非常高,因為要確保訊息剛好送達一次,需要複雜的協調機制,而這些機制本身也有失敗的可能性。業界的普遍做法是選擇 At-least-once(保證至少送達),然後在應用層實作冪等性來處理重複訊息,這樣能在可靠性和效能之間取得比較好的平衡。
Q8:CDN(內容遞送網路)對音樂串流服務有多重要? CDN 對 Spotify 這類全球性的串流服務幾乎是不可或缺的。沒有 CDN,台灣用戶播放一首歌的請求可能要繞到美國的伺服器,光是網路延遲就可能讓音樂無法即時播放。CDN 把熱門內容預先放到離用戶最近的節點,不只改善了使用體驗,也大幅降低了跨洲際的頻寬費用。
Q9:VPC Peering 的 Transitive Routing 限制有沒有替代方案? 有。Google Cloud 提供了 Cloud VPN 和 Cloud Interconnect 作為替代或補充方案,也有 Shared VPC 的架構可以讓多個專案共用同一個網路,減少需要建立 VPC Peering 的數量。另外,使用服務網格(Service Mesh)如 Anthos Service Mesh,也可以在不依賴 VPC Peering 的情況下管理服務間的通訊。
Q10:Spotify 的雲端遷移經驗適用於中小型公司嗎? 核心原則是適用的,但規模不同,決策的優先序也不同。對中小型公司來說,最重要的啟發可能是:善用雲端的全代管服務(Managed Services)來減少維運負擔,把有限的工程師資源集中在核心產品上;以及在技術選型初期就把擴展性和成本控制考慮進去,避免後期需要痛苦的架構大改。